Being frugal has benefits in terms of the effectiveness of the LLMs responses and the LLM API usage cost.
1. Single turn context
I’ve been tinkering with LLMs since the early days of GPT-4. My experience is that single turn prompts are more effective than long contexts.
The way my system works is that the Memento holds LSP references (e.g. symbol definitions, symbol references, etc.) or more general text fragments, and then a Classifier selects from the Memento which items are relevant for a given LLM prompt.
I saw that some providers show how much of the context is filled, or added the ability to do a sort of garbage collection of the LLM context. My understanding, and also my experience is that GC is needed not only for technical limitation but because it contains information that confuses the model. I don’t have that problem to begin with because the LLM requests are almost always single turn with a carefully curated context just for that request.
2. Zero files in context
I generally do not send files in the LLM request. Instead, as part of the planning workflow, the Memento is populated with the relevant file fragments that the LLM needs either to (a) read or (b) edit.
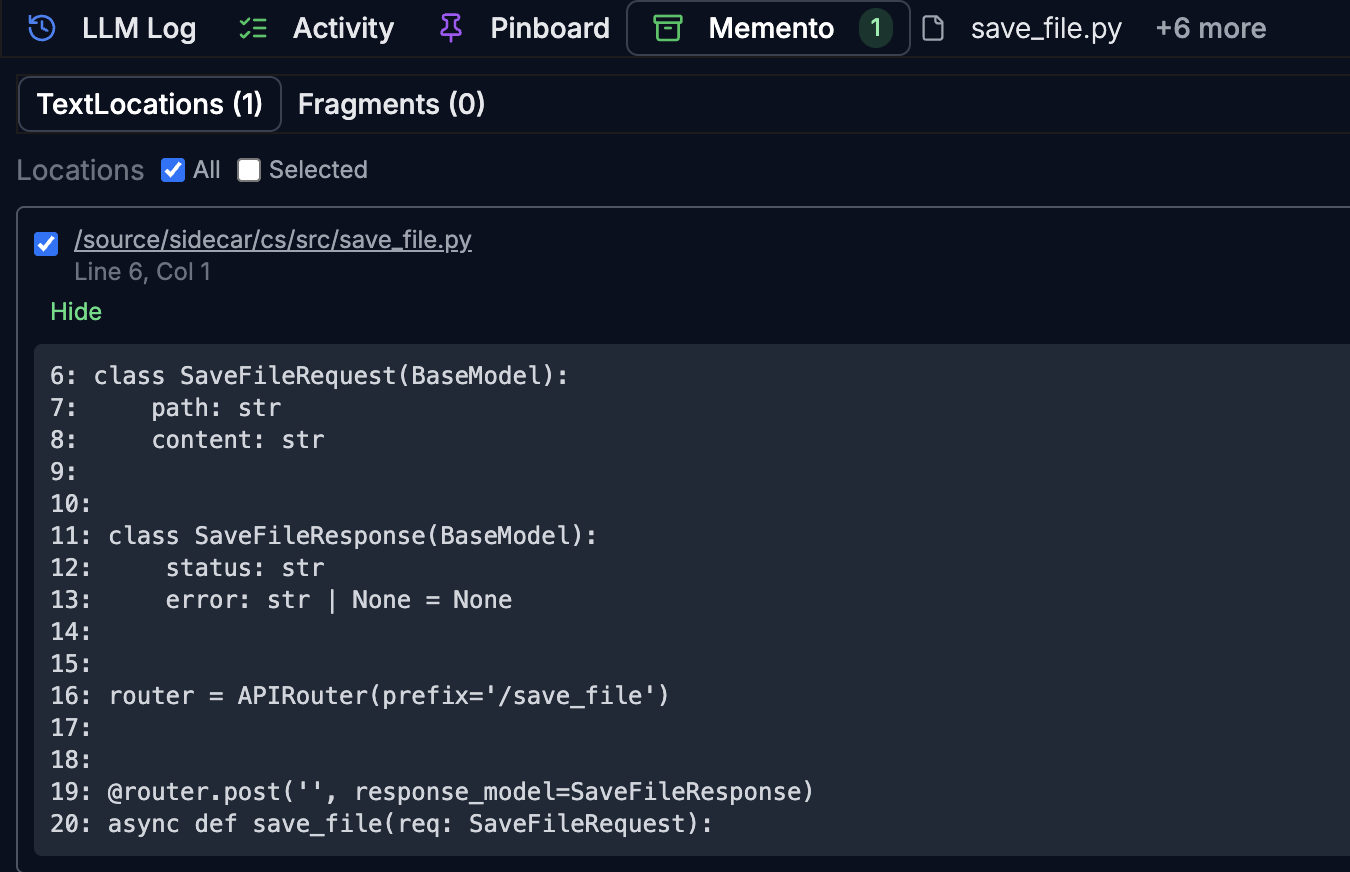
3. Response precision
My system is set up such that the agent can respond with vim-like commands, e.g. :10,20c. This way the output is in my experience significantly more precise and lower cost.
4. Flash models
I make heavy use of flash models for certain agents that do not require heavy inference-time capabilities. In the screenshot below, the Coder agent is configured with Claude Opus for example, while agents in the General category work really well with flash models.